By Rob Farber, contributing writer
As the word exascale implies, the forthcoming generation exascale supercomputer systems will deliver 1018 flop/s of scalable computing capability. All that computing capability will be for naught if the storage hardware and I/O software stack cannot meet the storage needs of applications running at scale—leaving applications either to drown in data when attempting to write to storage or starve while waiting to read data from storage.
Suren Byna, PI of the ExaIO project in the Exascale Computing Project (ECP) and computer staff scientist at Lawrence Berkeley National Laboratory, highlights the need for preparation to address the I/O needs of exascale supercomputers by noting that storage is typically the last subsystem available for testing on these systems. In addressing the I/O needs of many ECP software technology (ST), application development (AD), and hardware integration (HI) projects, Byna observes that the storage focused ExaIO project must prepare now to be ready when these systems enter production. “Success for the ExaIO project means addressing three trends that are becoming a gating factor at the exascale,” Byna said. “(1) too much data being generated, (2) too much data being consumed, and (3) the fact that storage performance is becoming a gating factor for many applications. Further, exascale-capable hardware solutions involve both novel and complex storage and I/O architectures that require enhancing existing I/O libraries. We are addressing these trends and hardware needs in ExaIO via the HDF5 [Hierarchical Data Format version 5] library and UnifyFS.”
Success for the ExaIO project means addressing three trends that are becoming a gating factor at the exascale: (1) too much data being generated, (2) too much data being consumed, and (3) the fact that storage performance is becoming a gating factor for many applications. Further, exascale-capable hardware solutions involve both novel and complex storage and I/O architectures that require enhancing existing I/O libraries. We are addressing these trends and hardware needs in ExaIO via the HDF5 library and UnifyFS – Suren Byna, PI of the ExaIO project and computer staff scientist at Lawrence Berkeley National Lab
Byna emphasized the importance of adapting I/O technologies so they are exascale ready, noting that “Without the funding provided by DOE and ECP to enhance the HDF5 I/O libraries, applications using HDF5 will not be able to take advantage of the novel exascale storage architectures. The funding gives us the ability to develop novel systems (like UnifyFS) that are pushing the I/O technologies into next generation. Byna also reflected on the breadth of technical support that arises from recognition of the general need for performant storage. “We are adding new features to HDF5, a popular data model, file format, and I/O library. The ExaIO team is also developing a new file system, called UnifyFS, for taking advantage of fast storage layers that are distributed across compute nodes in a supercomputing system. The project involves members from Lawrence Berkeley Lab, The HDF Group (THG) who is the main developer and maintainer of HDF5, Argonne National Laboratory, Lawrence Livermore Laboratory, Oak Ridge National Lab, and North Carolina State University.

Figure 1. Suren Byna, PI of the ECP ExaIO project and LBNL staff scientist.
A Multifaceted Approach to Deliver Exascale Readiness for Many ECP Projects
Recognizing that ECP workloads will present both diverse and demanding I/O behaviors, the ExaIO team is taking a multifaceted approach to ensure exascale readiness, as shown in Table 1. Their efforts start with the h5bench parallel I/O suite to evaluate high-performance computing (HPC)-like workloads and expand into the inclusion of performance-critical features such as asynchronous IO, parallel compression, and GPU I/O using NVIDIA GPUdirect. In addition, the team is adapting the hierarchical HDF5 storage library to utilize exascale hardware capabilities such as burst buffers.
| HDF5 component | Development status | Impact (Apps) | Systems used for testing |
|---|---|---|---|
| Virtual Object Layer (VOL) framework | Integrated in the HDF5 maintenance releases (1.12.x)
VOL 2.0 is in 1.13.0 pre-release | Enables using HDF5 on novel current and future storage systems easily (ExaIO, DataLib, ADIOS, and others) | Summit, Cori, Theta, Spock, and other testbeds |
| Asynchronous I/O | Released v.1.0 | Allows overlapping I/O latency with compute phase (EQSIM, AMReX apps, external) | Summit, Cori, Theta, Spock, Perlmutter, and other testbeds |
| Cache VOL | Released v.1.0 | Allows using node-local memory and/or storage for caching data (On systems w/ node-local memory/storage resources, ML apps) | Summit, Theta, and Cori |
| GPU I/O | Developed pluggable VFD in HDF5 (in 1.13.0 pre-release)
GPU I/O VFD v.1 is released | GPU I/O VFD allows using NVIDIA’s GPU Direct Storage (GDS) (Apps on GDS enabled GPUs, pluggable VFD allows developing new VFDs) | Tested on NVIDIA systems and a local server (Dependencies: GPUs that are GDS compatible and NVIDIA GDS driver installation) |
| Subfiling | Selection I/O has been implemented and integrated in HDF5
Implementation in progress | Allows writing/reading multiple subfiles (instead of single shared file) (Testing w/ h5bench) | Testing on Summit and Cori |
| Multi-dataset I/O API | A prototype available; design updates in progress | Allows writing multiple HDF5 datasets with a single write/read call (E3SM) | Prototype was tested on Summit and on Cori with E3SM F and G case configurations |
| h5bench | Released v.1.1 | Allows testing a diverse set of I/O patterns and app kernels with various HDF5 features (Broad) | Summit, Theta, Perlmutter |
| Parallel compression | Released in HDF5 maintenance | Evaluating performance and tuning as needed (EQSIM, AMReX applications, and others) | Evaluating performance on Summit and Cori with EQSIM checkpointing using ZFP compression |
Table 1. ExaIO component status for exascale readiness. Green indicates in the internal HDF5 library. Blue represents external plugins and connectors. Gray indicates ExaIO efforts.
As with all computer systems, I/O robustness is a requirement: storage systems cannot lose or corrupt data. To ensure the highest levels of reliability across ECP-supported hardware, all products and features in the ExaIO project have been included in the ECP Continuous Integration (CI) effort. The ECP CI project automates building and testing of the ECP software ecosystem at various US Department of Energy (DOE) facilities. This includes modifying the ExaIO software so that it can be built with SPACK (a package manager for supercomputers)[i] and incorporated as an integral part of E4S (a curated source of tested open-source software components) to ensure general availability and ease of installation for both DOE and general HPC users.
ExaIO team members actively work with various ECP teams to support them in their efforts to integrate and deploy the ExaIO features in numerous projects. A few examples are shown in the table below. (Click on the hyperlink in each cell to learn more about these projects.)
| ECP AD Team | Type of Engagement | Status |
|---|---|---|
| ECP AD Team | Type of Engagement | Status |
| EQSIM | Development of I/O framework based on HDF5 | Implemented most of the components, tuning at large scale |
| AMReX | Development of HDF5 I/O | Implemented HDF5 I/O, adding compression |
| QMCPACK (KPP-3) | File close performance issue | Improved performance |
| Subsurface simulation | I/O performance tuning | Improved performance |
| FLASH-X | Implemented async I/O routines | Testing performance at large scale |
| ExaSky – HACC | I/O performance tuning | Tuning performance – subfiling |
| WarpX / OpenPMD | Tuning HDF5 I/O performance of OpenPMD | Tuned I/O performance by 10X for a benchmark; more potential for performance improvement |
| E3SM | Improving HDF5 performance | Identified multi-dataset API improves performance; tuning further |
| Lattice QCD, NWChemEx, CANDLE | I/O using HDF5 | Initial communications w/ the AD teams |
| ExaLearn | I/O for ML applications | Performance evaluation and testing cache VOL |
| ECP ST Team (ST and HI efforts) | Type of Engagement | Status |
| ADIOS | Interoperability of HDF5 and other file formats | •VOL to read ADIOS-BP data •ADIOS R/W of HDF5 data •Future work on HDF5 using in situ capabilities |
| Interoperability of HDF5 and other file formats | •VOL to read PnetCDF data •HDF5 relies on MPI-IO •Darshan profiling for HDF5 •Using Argobots for async I/O VOL | |
| ALPINE – EZ | Compression in HDF5 | EZ team developing parallel filter with HDF5 |
| ALPINE/ZFP | Compression in HDF5 | Testing zfp with EQSIM - good compression ratios |
| ALPINE | VTK / HDF5 mapping | ALPINE team is developing an HDF5 mapping for VTK data structures (Data & Vis SDK) |
| ExaIO – HDF5 + UnifyFS | HDF5 API with UnifyFS backend | Designing and implementing UnifyFS API |
| HI – ST App Integration project | Benchmarking and I/O performance monitoring | Adding more benchmarks to h5bench and testing on pre-exascale systems |
Table 2. Current ExaIO team engagements and status as of March 2022.
UnifyFS provides a Shared Filesystem Namespace
UnifyFS is a user-level file system that supports shared file I/O to fast, scalable, node-local burst buffer storage media as well as distributed storage.
Burst buffers are an architectural feature that has been added to modern supercomputers. They provide a fast intermediate storage layer, located on each computing node, that can handle “bursty” I/O patterns. They are important to exascale machines because burst buffers can greatly speed up common HPC I/O patterns such as checkpoint/restart and other bulk synchronous I/O workloads.[ii]
Checkpoint operations, for example, are commonly used as an application prophylactic measure to periodically save the state of the computation on each node. Should any node in a large, distributed computation fail, the application can be restarted from the last known state in the checkpoint. Exascale supercomputers utilize large numbers of compute nodes to deliver their tremendous computing power. As applications scale out to run across many computational nodes, the probability of failure in a single node—though small—increases given the long runtimes of many HPC applications. Software checkpoints prevent the loss of large amounts of supercomputer time should a hardware or software failure occur. Many HPC systems utilize burst buffers to accelerate these checkpoint operations, including the forthcoming generation of exascale supercomputers. Not only do burst buffers provide extremely fast I/O capability, but their per-node design means this I/O capability can scale in an unlimited fashion to clusters of arbitrary size.
The UnifyFS project led by Kathryn Mohror, Computer Scientist at Lawrence Livermore National Laboratory, adds a file system interface so applications can directly access burst buffer media. This makes it easy to implement fast, scalable checkpoints and accelerate hierarchical storage libraries such as HDF5 by simply using filesystem names and paths.

Figure 2. Kathryn Mohror, Computer Scientist at Lawrence Livermore National Laboratory.
UnifyFS presents the user with a shared namespace where the type of storage media (burst buffer or distributed storage) is selected via the mountpoint. This makes it easy to adapt existing codes to use both distributed and burst buffer storage. Libraries such as HDF5, for example, can be modified to use burst buffer storage as the upper, fastest tier in the storage hierarchy.
The performance difference is substantial, as shown in Figure 3, which compares UnifyFS write performance to burst buffer media against the write performance to the distributed GPFS file system. In this test, UnifyFS delivered a 53× performance improvement over the distributed GPFS file system. Overall, the ExaIO team reports that UnifyFS outperforms GPFS at all scales.
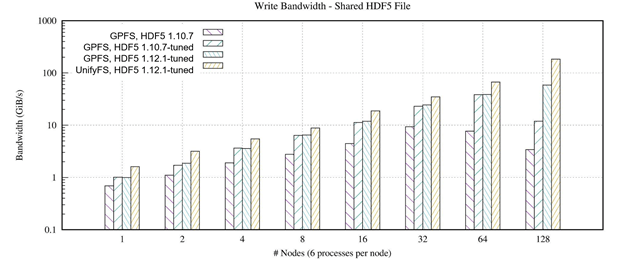
Figure 3. Write speed comparison of UnifyFS vs GPFS for varying numbers of nodes.
These new levels of I/O scalability and performance are needed. “Until recently, scientists have largely been able to ignore I/O as a minor overhead in simulation time,” Mohror noted. “Now, advances in HPC system compute architectures enable simulations to perform increasingly higher-fidelity computations very quickly, and the simulations are producing and consuming data at unprecedented rates. We need to address the challenges of increased I/O needs now so that we don’t reach a state where scientists are unable to produce and analyze data in a tractable way in the exascale era.”
Until recently, scientists have largely been able to ignore I/O as a minor overhead in simulation time. Now, advances in HPC system compute architectures enable simulations to perform increasingly higher-fidelity computations very quickly and the simulations are producing and consuming data at unprecedented rates. We need to address the challenges of increased I/O needs now so that we don’t reach a state where scientists are unable to produce and analyze data in a tractable way in the exascale era. – Kathryn Mohror, Computer Scientist at Lawrence Livermore National Laboratory
UnifyFS is an “ephemeral filesystem,” which means that it starts and stops with the user application. The advantage is very fast startup of the filesystem and direct I/O from userspace. Data is flushed to persistent storage when job finished.
ExaIO Implements Production Quality HDF5 Features
HDF5 is a popular I/O library that provides an application programming interface (API) and a portable file format. A mature software project, HDF5 has been around for more than 20 years. It is used by several ECP applications as well as tens of thousands of applications in various science areas and industry. The self-describing and portable file format of HDF5 are the most attractive features for maintaining data storage for long-term use. The impact of enhancing HDF5 will reach a broad community.[iii]
The ExaIO team is targeting the following HDF5 enhancements:
- Make the HDF5 API available to new storage technologies as well as new file formats, referred to as the HDF5 Virtual Object Layer or VOL, which has now been released in HDF5. The VOL framework gives other I/O libraries, such as ADIOS and DAOS, the ability to use the versatile HDF5 API and store data in different file formats.
- Develop caching and prefetching technologies to take advantage of deep memory and storage hierarchies as well as temporary file systems, such as UnifyFS, for high performance. The ExaIO team notes that this can improve I/O performance by 3× to 20×.
- Incorporate asynchronous I/O (discussed below) to hide the latency and reduce application time to solution in performing I/O by overlapping the I/O operations behind computing. Byna observes that most of the I/O time can be overlapped in applications that interleave computation and I/O phases.
Recent Project Successes
The ExaIO team reports many successes with software developers tuning their existing HDF5 usage to ECP architectures. This includes both using the existing features efficiently and applying new features added by the ExaIO team. Baseline applications include the ECP Earthquake Simulation (EQSIM) application, cosmology simulations such as Nyx and Castro, as well as multi-physics applications such as FLASH-X, quantum Monte Carlo simulations with QMCPACK, and climate simulation frameworks such as E3SM.
“Based on our experience observing how these applications use HDF5, the ExaIO team has also developed a suite of benchmarks called h5bench that the user community can use for tuning HDF5 on their systems,” Byna noted.
Based on our experience observing how these applications use HDF5, the ExaIO team has also developed a suite of benchmarks called h5bench that the community can use for tuning HDF5 on their systems. – Suren Byna
EQSIM
The EQSIM application development team is creating a computational tool set and workflow for earthquake hazard and risk assessment that moves beyond the traditional empirically based techniques that are dependent on historical earthquake data.[iv] Working in collaboration with ECP’s software technology group, the EQSIM team is working to give scientists and engineers the ability to simulate full end-to-end earthquake processes.
The ExaIO team is a key part of that collaboration. As a baseline, the ExaIO HDF5 library has delivered numerous benefits to the EQSIM project including reducing input time from hours to minutes, as verified by a 3,600 node run on the pre-exascale Summit supercomputer. Transparent compression provided a 13× performance improvement and a greater than 260 compression ratio. The HDF5 self-describing format and portability allows convenient data sharing among scientists who use EQSIM. The team reports that the using burst buffers delivers a 5× to 9× performance boost on the Cori supercomputer and a 20% increase in performance on the Summit supercomputer.
The workflow and performance benefits are summarized in the following slide from the ExaIO December 2021 project review.
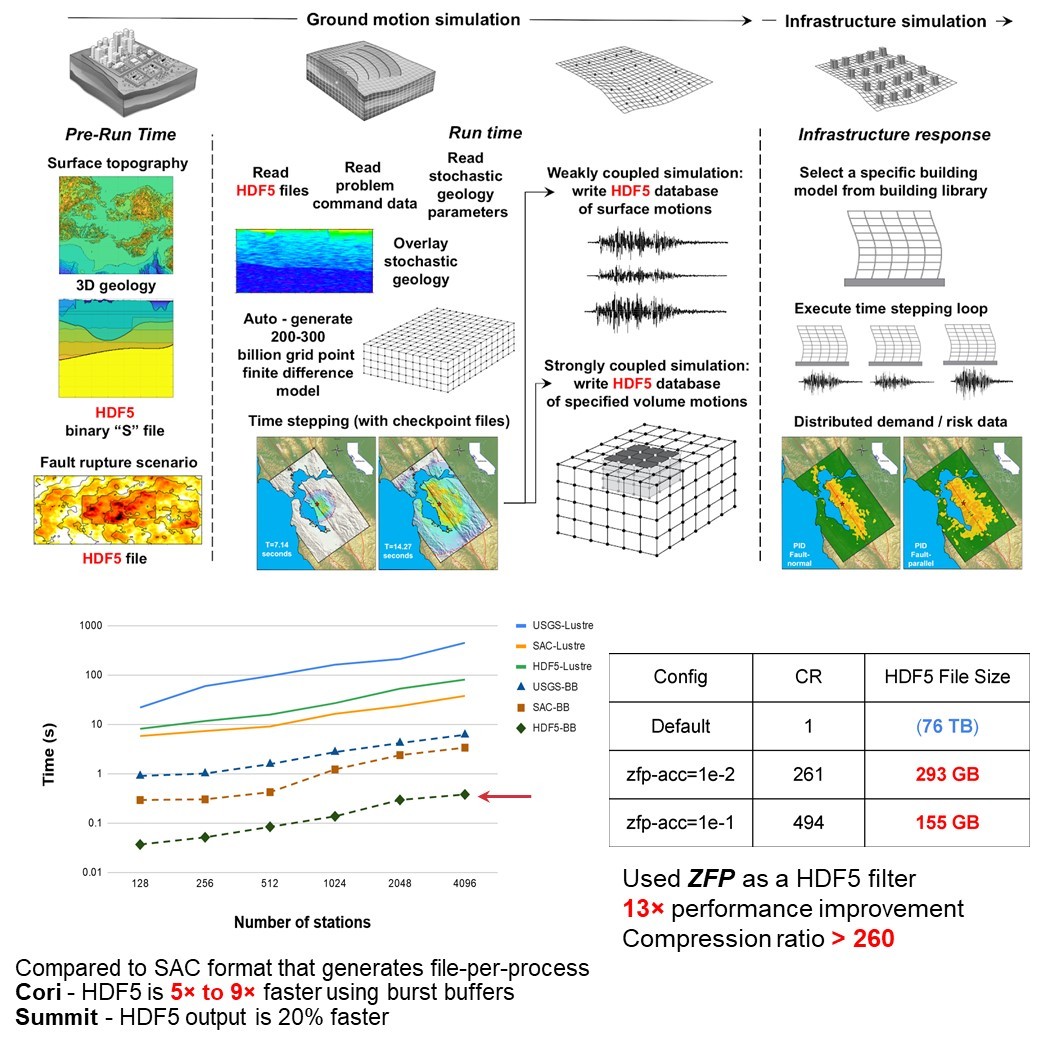
Figure 4. HDF5 library and compression benefits to the EQSIM workflow. The application point of contacts are D. McCallen, H. Tang, and N. Petersson.
AMReX
AMReX is a software framework containing all the functionality to write massively parallel, block-structured adaptive mesh refinement (AMR) applications. AMReX is freely available on GitHub. It supports five ECP AD projects—WarpX, ExaStar, Pele, ExaSky, and MFIX-Exa.
The ExaSky project, which uses AMReX, is one of the critical Earth and Space Science applications being solved by the ECP. “The ExaSky team is adapting our Lagrangian-based Hardware/Hybrid Accelerated Cosmology Code (HACC) and adaptive mesh refinement cosmology codes (Nyx) to run on GPU-accelerated exascale hardware,” noted Salman Habib, the director of Argonne’s Computational Science Division and an Argonne Distinguished Fellow. “These machines will give us the ability to incorporate more complex physics arising from diverse inputs, such as the presence of massive neutrinos, models of star and galaxy formation, and several sources of astrophysical feedback, such as active galactic nuclei, galactic winds, and supernova explosions.”[v]
The ExaIO team is developing and tuning the HDF5 I/O for AMReX, which in turn benefits components used in the ExaSky project. The upgraded HDF5 I/O with asynchronous I/O that effectively overlaps I/O latency with computations currently delivers a 4× speedup for five time steps, as seen in Figure 5. This is a work in progress including efforts by the ExaIO team to update the file layout to achieve better compression of the data.
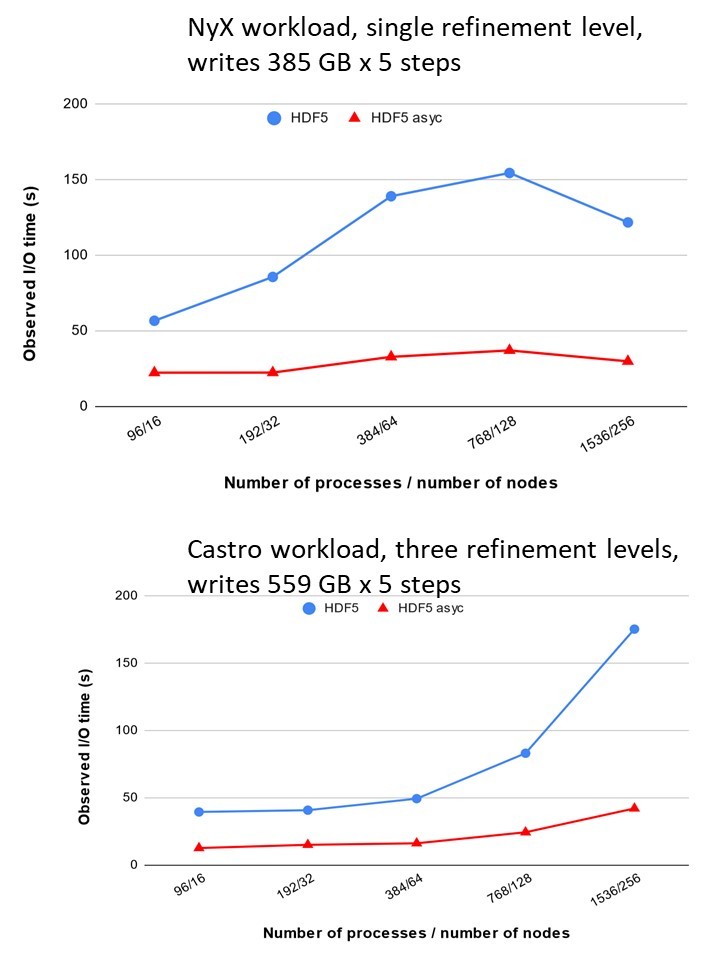
Figure 5. Representative benefits of asynchronous I/O to the NyX workload. The application point of contracts are A. Almgren, A. Myers, Z. Lucic, J. Sexton, and K. Gott.
Asynchronous I/O
Asynchronous I/O gives developers another tool to exploit hardware parallelism to achieve higher performance and faster time to solution. The ExaIO team has built and tested asynchronous I/O on all major platforms and exascale testbeds, including Summit, Spock, Cori, Perlmutter, and other testbeds. More information and example can be found on GitHub.
Figure 6 illustrates how asynchronous I/O operations can save time to deliver a faster application time to solution. Keep in mind that I/O operations typically occur orders of magnitude slower than the time it takes to access data from main memory. Not only is external I/O slow, but it is also strongly affected by the amount of the data transferred during the I/O operation. As scientists utilize larger data sets on pre- and post-exascale supercomputers, the length of the write blocks for synchronous write operations (notated by the “Sync” timeline) illustrated in the figure below will increase and can become significantly longer. This reflects how an application can become seriously I/O bound on an exascale supercomputer as the size of the I/O operations increase.
In comparison, asynchronous I/O operations give programmers the ability to initiate I/O operations so that I/O operations occur concurrently (e.g., in parallel) with the computation. The asynchronous example in Figure 6, notated by “Async,” illustrates the time savings realized by not having to stop a computation while waiting for an I/O operation to occur. Read operations (not shown) can also occur asynchronously via a fetch operation initiated by the application far enough in advance so the computation does not have to pause waiting for a read I/O operation to occur.
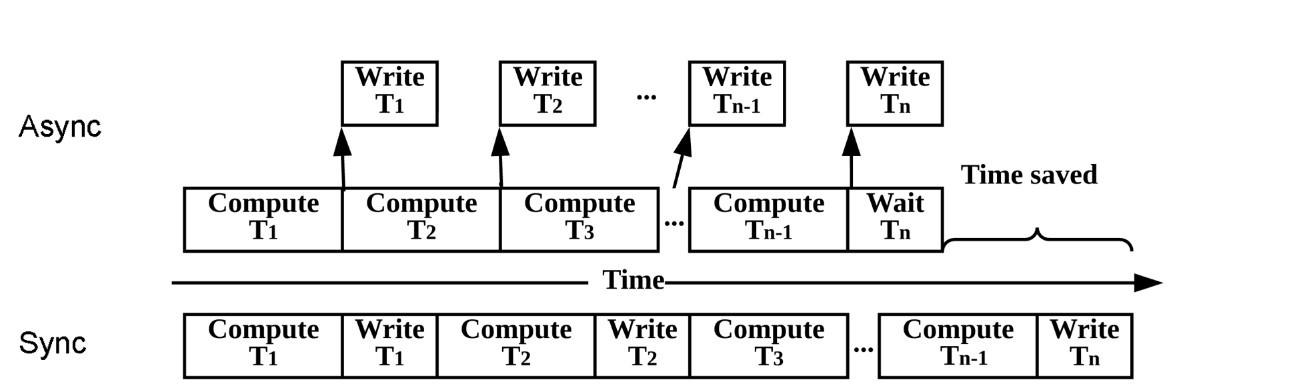
Figure 6. Illustration of the time-savings that can be achieved with asynchronous I/O.
Summary
I/O is required and hence ubiquitous in computing. Data volumes are increasing dramatically as scientists move to investigate phenomena with greater detail and fidelity. This means that the I/O software and hardware subsystems need to keep up; otherwise, much of the runtime of an application can be spent reading and writing data. Turning applications into I/O-bound rather than compute-bound problems obviates the extraordinary computational capabilities of pre- and post-exascale leadership-class supercomputers.
ExaIO is designed to utilize the new exascale architectures including novel memory and scaling capabilities to deliver very large, very performant I/O. These advances in I/O are needed to meet the needs of the increased data volumes that modern supercomputers can handle. In combination, the ExaIO and UnifyFS teams are working to:
- Ensure that existing projects can start running immediately when exascale systems are accepted through integration and testing on existing systems.
- Adapt the HDF5 API so that it can use new storage technologies and I/O libraries.
For more information
- Recent publications by the ExaIO team can be found at: https://sdm.lbl.gov/sbyna/
- Look to ExaIO GitHub for information about other features:
- transparent data caching
- topology-aware IO
- full single-writer and multi-reader for workflows
- GPU I/O (using GPUdirect)
- Look to the UnifyFS GitHub for detailed information about this project.
This research was supported by the Exascale Computing Project (17-SC-20-SC), a joint project of the U.S. Department of Energy’s Office of Science and National Nuclear Security Administration, responsible for delivering a capable exascale ecosystem, including software, applications, and hardware technology, to support the nation’s exascale computing imperative.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations.
[ii] https://unifyfs.readthedocs.io/en/latest/overview.html
[iii] https://www.hdfgroup.org/solutions/hdf5/
[iv] https://www.exascaleproject.org/highlight/eqsim-on-leadership-supercomputers-gives-engineers-the-end-to-end-ability-to-assess-infrastructure-risk-from-earthquakes/
[v] https://www.exascaleproject.org/highlight/verifying-the-universe-with-exascale-supercomputers/